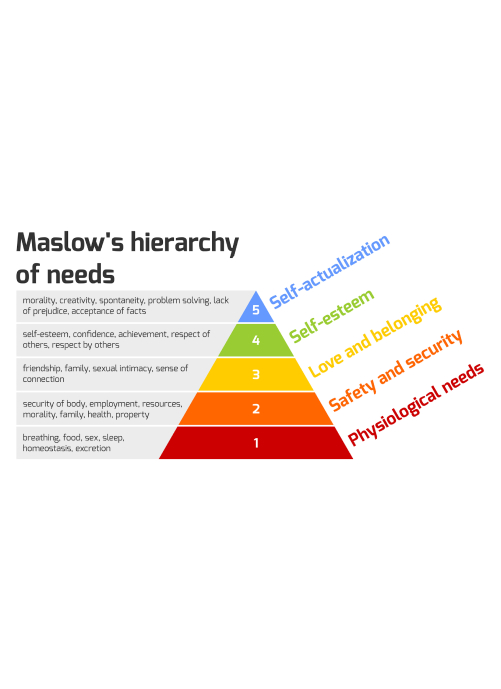
Sydney Perelmutter:
Thank you all for that very insightful presentation and I would like to continue to ask our audience to continue sending in their questions for the Q&A portion of the webinar. But I've already received many questions, so I'll start with our first one. Our first question is, what are the current challenges in reconciling different RWD collected using a variety of recording techniques and technologies within RWE studies?
Gaelan Ritter:
Who wants to go first? I can jump in with some of the challenges that we see, I guess.
I think one of the things we see is that disparate data acquisition sources can have different….it's not that the data's conflicting, it's that the data's collected with different intent, so if you had a patient-reported symptom versus a clinician reported symptom, those are going to look different. Even though they might be getting to the same underlying part of the disease, they're going to be represented differently and we see that across different types of real-world data. So you'll see a very different kind of catalog of information from a patient-entered source versus a site-entered source. We see the same thing when you start looking at the kind of linkages between datasets that have different intended end uses. So a claims data set is going to represent a disease state very differently than an EHR dataset because they're intended for different purposes.
We actually see a lot of data that needs more, rather than cleaning, it needs concordance. And so we see that a lot more often now as you're starting to, like Andrew mentioned, starting to tokenize and link different data sets that had different reasons for existing. You're starting to kind of see the emergence of a lot of need for harmonization across those, and that takes a little bit more sophisticated effort than just a mapping table in controlled terminologies. So I think that's something that's emerging more for us as we start to get into these more complex, compiled real-world data sets.
Andrew Larsen:
Yeah. I think that's all right. And what Gaelan teed up earlier where it's like data acquisition is one of the challenges. I think the first step for PicnicHealth at least, a lot of because we collect medical records across any care facility, rural PCP versus like high-end academic institution, and part of what we have really put a lot of thought and energy to is like, how do we actually harmonize these data sets, these different disparate data sources into a single usable data set? I think as we've overcome that challenge, the exact next one is sort of concordance and it's like how do you reconcile all of these different pieces of information with different intent? I think our sort of fallback is there is no silver bullet. It's very much like, what is the question you're asking and what are the pieces of information that should be indexed on to best actually reach a defendable conclusion? I'll stop. I'll end it there and I'm sure there's probably a lot left unsaid there, but happy to discuss further if interested.
Sydney Perelmutter:
Thank you for those answers. Another audience member would like to know, what are your thoughts and what are you seeing with sponsors using registry or open access patient journey data as quote unquote "placebo group" for open-label studies?
Gaelan Ritter:
I'll start this one too, I guess. One of the things…so we are seeing more and more of that. You're seeing a lot of [this] especially in rare diseases. If it's hard enough to find patients to participate in the trial and treatment arms of some of these diseases, being able to find patients to participate in control arms is next to impossible. And especially we're seeing more and more that obviously clinical trials are becoming a therapeutic alternative, especially in rare disease and in late stage disease, and because of that, in those assets you literally don't have many patients that aren't part of clinical trials. We're seeing a lot more use of those data sets both in the classic kind of external control space, but then also seeing them being used as–whether it's digital twins or other types of capabilities that are emerging–to be able to provide insight about the patients on the treatment arm of the trial without having to classically enroll like you would for other trials.
You're seeing that emerge in a lot of ways, whether that's in hybrid control models, synthetic models, and like the digital twin model. It's actually been very beneficial though, to be totally honest, because getting drugs to patients that are in rare diseases is critically important, and the timing is so frustrating because delays in those–there are no other alternatives for those patients–so delays in those asset journeys literally impacts people's lives, and so being able to kind of build bodies of evidence through new statistical techniques has been a real benefit to a lot of those patient groups.
Sneha Kishnani:
Yeah. I mean, I can add to this one. We do see this all the time with respect to disease registries as well as natural history of disease studies that are also being run in addition to any kind of broader registry. I think that there is an acceptability around it and it's happening more and more.
Andrew Larsen:
Yeah. I would just say I think at least for the last three years, every year there's been at least one drug approved with this sort of approach, so I think while regulatory guidance still always indexes on preferential sort of the ability to have a classically randomized controlled trial with a placebo or standard of care arm, I think this is something where when you actually…you have to consider on a case-by-case basis is like, is this truly a landscape where the sort of unmet need and the actual feasibility considerations for a trial justify this? I think we've consistently seen an openness to that, which is great for patients. I think then there's getting that initial access to patients, whether it's an accelerated approval potentially, and then there's the follow-on confirmatory studies, which can take a very long time, right? But I think usually there's that consideration where it's like, let's do the right thing now based on this body of evidence that we feel comfortable doing it, and then confirmatory studies as appropriate for any outstanding questions.
Sydney Perelmutter:
Thank you. Again, we have a question for Gaelan specifically and then we'll do one more question. That question for Gaelan is, can you talk about innovative ways that can help to identify the best participant for a research study?
Gaelan Ritter:
Sure. Absolutely. We're doing a lot more with using access to EHR records and to claims records to be able to map where patients are. Some of that is kind of just looking at population dynamics and heat mapping and then taking the next level and deploying algorithms that actually search medical records for patients that meet not only the I/E criteria of the study but look like patient groups that we've seen in previous trials that would benefit from those studies. So it's really kind of about leveraging that EHR data access and the real-world data sources that we have and being able to create algorithms that look for those best fits. It's a lot of the work that the clinical research coordinators and investigators do manually today, which takes an enormous amount of their time, and so being able to automate some of that and present them with those best fits has been a real advantage and a real opportunity for all of us.
Sydney Perelmutter:
All right. We have time for one more question. We've talked comparisons and differences across patient mediated vs. tokenized vs. traditional site-based approaches, so can you all share some examples of if or how these approaches can be used together?
Evelyn Pyper:
I guess maybe a question to that question that I would put out there is, if the spectrum between site-based and decentralized has infinite points in between it, what does that kind of ideal hybrid model look like to folks on the call? It feels like it could be so many things. The way… patient mediated data is not the antithesis of collecting site-based data, so what does that ideal hybrid look like?
Sneha Kishnani:
I think there is no ideal hybrid. Right? I think that's the beauty of ‘hybrid’ is it can be what it needs to be for whatever research question we're trying to answer. It's having the awareness around, what are the different data types and data sources out there. And having the deep insight and the deep knowledge into: does that data source have the information that is going to help us to answer the question that we want, and where do we need to get the data from? So in essence, looking at a protocol, looking at the study objectives, the endpoints you're after and understanding who is the right source of all of this data? Does it need to come from a site? Can it come from the EMR? You know, et cetera. So really understanding deeply where that data lives and who can best provide it in an accurate and high quality way.
Andrew Larsen:
Yeah. I echo that same thought. I mean, it has to be fit-for-purpose. What are the questions? What are the data sources that support it? And really think critically about the feasibility of what you're considering, right? Just because a data source has ‘data element X’, are you actually going to get the coverage you need or the temporality you need for the patient populations that match? I think being diligent pays off and makes this all a much easier process downstream.
Sydney Perelmutter:
All right. Well, thank you very much for those answers. This concludes the Q&A portion of this webinar, and if we couldn't attend to your questions, the team at PicnicHealth may follow up with you, or if you have further questions, you can direct them to the email address on your screen. Thank you everyone for participating in today's webinar. You'll be receiving a follow-up email from Xtalks with access to the recorded archive for this event and the survey window will be popping up on your screen and your participation is appreciated as it will help us to improve our webinars. Now, please join us in thanking our speakers, Gaelan Ritter, Sneha Kishnani, Andrew Larsen and Evelyn Pyper. We hope you found this webinar informative. Have a great day everyone.